The Beginner’s Guide to Command and Control Part 1 – How C2 Frameworks Operate

Introduction
Welcome to the first installment in a comprehensive multi-part series introducing Command and Control (C2) frameworks to beginners. While I’ll cover technical details, my goal isn’t to simply regurgitate information you could find with a quick Google search.
I’ve personally always derived the most value from articles and presentations that explain familiar concepts in fresh, novel ways. My belief is that technical understanding can only truly be derived from praxis, so the goal of this series is to help strengthen the conceptual scaffolding upon which said technical understanding can later be built.
Throughout this series, my hope is to help you develop a clear, intuitive understanding of what C2 frameworks are, how they work, what their purpose is, and why they matter. This first article takes a holistic approach, exploring how these frameworks function at a systems level. Specifically, I want to examine the architecture and logical flow that makes them so powerful.
Let’s do this.
Let’s Begin with a Quote
One of my favorite “security quotes” is by Active Countermeasures’ very own fearless leader, Chris Brenton:
“Malware does not break the rules, but bends them.”
It’s one of those insights that, once you see, you can’t unsee. It’s evident everywhere, whether on the network or the endpoint.
What this quote captures, among other things, is that there’s nothing fundamentally unique about malware code. Malicious software uses the coding practices and idiomatic conventions as legitimate applications. Malware doesn’t possess some black magic allowing it to do impossible things; rather, it does things that “should not” be done, but technically can be done.
Viewed through this lens, C2 frameworks are essentially just Client + Server models—the same architectural construct used in countless applications that enable communication between hosts across networks.
But before we dive into this larger concept, I want to take a quick moment to answer an even more elementary question – what exactly is a Client + Server model?
The Client + Server Model
Usually when we’re taught what a client and server is, we’re shown some diagram like this:
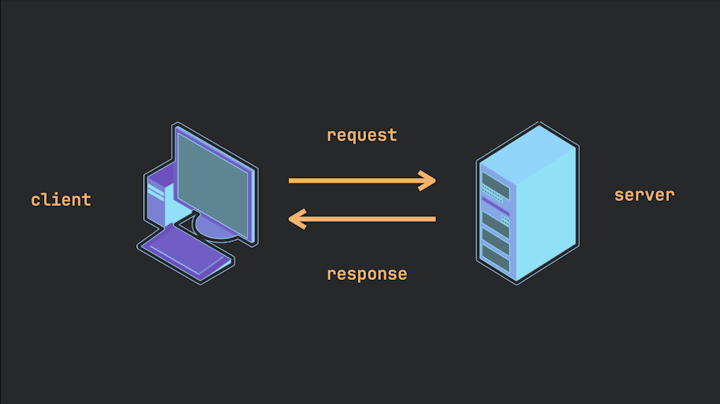
Image 1.
The image shows a classic scenario where: On one side is a desktop, laptop, or phone representing the client. On the opposite side sits a server—depicted as a box without a screen, or perhaps a server rack. We’re told that the client (the machine we use to for example browse YouTube) sends requests to a server, which responds with the video we requested.
And this model we’re usually taught isn’t wrong – it’s literally correct. That is a client and a server, and an extremely common instance of it. But it’s like I was teaching you what “combustion-driven locomotion” is by showing you a picture of a Honda Civic. Technically correct, but a limiting perspective – it’s mistaking a discrete instance for a more universal concept.
So for the moment, I want us to forget this technically accurate, though somewhat limiting interpretation of what client and server is, since I think there’s a lot of value in understanding the universal concept.
The first key point: being a client or a server is not an intrinsic or immutable characteristic of a device. “Client and server” simply describes a relationship—more precisely, a relationship at a specific moment in time.
Now if this sounds confusing, allow me to use a metaphor that might seem totally out of left field, but which I think will make it clear how simple this idea actually is.
The Act of Giving and Receiving a Massage
The metaphor I want to use is the act of giving and receiving a massage. I’ve asked two fellow Canadians, Terence and Philip, to join us for this demonstration.

Image 2.
Note that I learned while preparing this article that “masseuse” is considered outdated terminology, so let’s refer to the person giving the massage as the “massage provider,” and the person receiving it as the “massage recipient.”
If we look at Terence and Philip above in Image 2 and I ask you who is the massage provider and who is the recipient, there’s no way to tell. Now imagine that we observe them a moment longer and then this happens…

Image 3.
Now it’s clear: Terence is the massage provider, and Philip is the recipient. But let’s say we step away briefly, and when we return…

Image 4.
Now if I asked you who’s the provider and who’s the recipient, your answer would be reversed.
So if we see Terence and Philip just standing there as they do in Image 2 and I ask who is the provider and who is the recipient, you’d correctly say, “It depends.” It depends on who is giving the massage and who is receiving it.
This illustrates that being a massage provider or recipient isn’t an immutable or intrinsic characteristic—it’s a description of a relationship at a specific moment in time. That said, this doesn’t mean both Terence and Philip are equally suited for the massage provider role.
Terence might genuinely enjoy and excel at giving massages. He might have formal training in different techniques. He might have developed hand and forearm strength for giving massages for hours. He might even identify professionally as a “massage therapist” and introduce himself that way at dinner parties.
Back to Our Client and Server
If we now return to our earlier diagram from Image 1, this same principle applies—client and server are simply descriptions of a relationship. Instead of being based on who gives and receives a massage, it’s based on who sends the request (the client) and who responds to that request (the server).
Meaning that if we took this exact same diagram but the machine on the right made the request, it would become the client—and if the machine on the left responded, it would be the server.
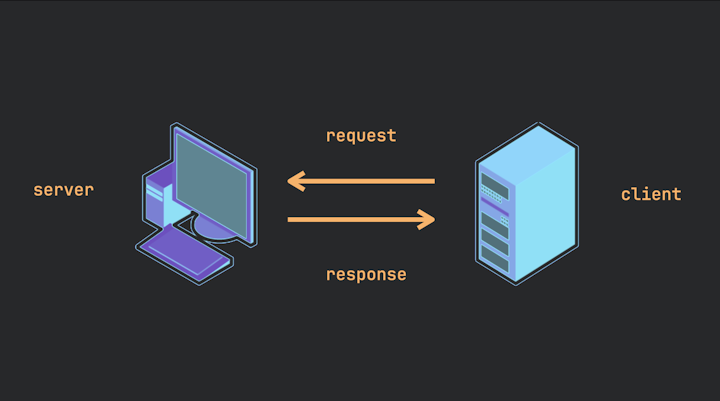
Image 5.
But, just as some people make better massage providers than others, some machines are better suited to being servers. That’s why we typically see diagrams like the one in Image 1—the machine on the right is hardware-optimized for server functions, while the one on the left is better suited as a client. But remember: being “more suitable” doesn’t mean “immutably so.”
And so finally if we ask ourselves what makes one machine send a request and the other be able to respond to it – well it of course has nothing to do with the hardware.
The answer is software: It’s the code on one machine that sends a request to another. And it’s the code on that other machine that receives the request, processes it, and then responds.
So while our typical mental model involves thinking of a client and server as two machines, what I want to propose now is that you think of a client and server as two applications – one that sends requests, and another that responds to it.
And so with all this in mind, let’s now explore how a C2 works.
Let’s Set the Stage
Let’s imagine that this green area below on the right represents a corporate LAN:

Image 6.
What makes this a LAN? First, it contains a local host—one of likely many computers on this network, but for simplicity, we’ll focus just on this particular machine.
What also defines it as a LAN is its separation from the outside world, that is from all other networks, by a single entry and exit point: a firewall. In other words – all communication flowing into or out of the LAN must pass through this gateway.
In reality, this corporate network probably contains multiple segments, additional routers, and various switches forming a complex infrastructure. However, for now let’s just focus on this single node that separates internal hosts from everything external.
Initial Access
Now we have our corporate LAN with a local host protected by a firewall. Let’s imagine the person working on this host receives a phishing email. They click the attachment, eager to see a supposed “job offer,” so they enable macros, and boom—a malicious script executes.
What’s the first thing this script does? It connects outbound, passing through the firewall to the internet, where it reaches another application it was programmed to contact.
Since this initial payload (being a macro script) is typically small and limited, it’s likely a “staged” payload. This means its primary job is to download the “real” application, inject it into memory, and execute it.

Image 7.
We now have an application on the victim system connecting outbound and sending requests to another application on the external system, which responds to these requests.
Request, response, request, response, request, response…

Image 8.
Get it?
The host on the left (the attacker’s system) is the C2 Server, and the one on the right (the victim system inside the corporate network) is the C2 Client.
The Direction Matters
Now we’ll soon unpack the C2 server and client in more depth, but while we’re here I want to emphasize that the direction of communication is crucial. The victim system must be the one that connects outbound, sends requests, and acts as the client. This is because any properly configured firewall will block random inbound connection attempts to internal hosts.
However, since most systems on a corporate network need to access external websites (whose IP addresses may change), firewalls typically allow outbound connections, especially over HTTP or HTTPS.
There are security measures that might restrict this outbound traffic. Proxies with blacklists might be implemented, meaning the external C2 server cannot be on a known-bad list. In more strict environments, administrators might employ whitelists, where users may only connect to specifically approved domains.
Even these restrictions can be circumvented through techniques like domain fronting or leveraging trusted Content Delivery Networks (CDNs). Domain fronting allows the malicious traffic to appear as though it’s communicating with a legitimate, trusted domain while actually connecting to the attacker’s infrastructure.
While there are exceptions like tunneling that might bypass the outbound connection requirement, the general rule remains: the victim system (inside the protected network) must initiate the connection outbound to the attacker’s system. This fundamental aspect of C2 architecture is what allows it to bypass many common security controls.
C2 Agent Terminology
A quick note on terminology regarding the C2 client. While technically this component functions as a client by sending requests to the C2 server, security professionals rarely use the term “C2 client” in practice. Instead, this component goes by many different names, as various C2 frameworks tend to create their own terminology.
Cobalt Strike calls these components Beacons. Havoc refers to them as Demons. Covenant uses the term Grunts. Sliver calls them Implants. Perhaps the most widely used term across the industry, and the one I prefer and will use throughout this series, is “C2 Agent.” I prefer this term since I think it effectively captures its role as an autonomous program operating on behalf of the attacker. Note however that you’ll also very commonly hear the term implant being used, especially when referring to this application’s actions in relation to the endpoint.
Whatever the specific term you prefer or encounter, remember that it’s still technically functioning as a client in a client-server relationship.
The “Real” C2 Client
Now speaking of clients… In most C2 frameworks, the operator (the person using the framework) doesn’t interface directly with the server. The server functions as a central command center—the logical node of the entire operation. However, when an operator wants to create new listeners or issue commands to an agent, they typically do so through a different host running the user interface (UI) or frontend.
Interestingly, this host running the frontend is what’s typically called the “C2 client.” This might initially seem confusing, but remember that client and server is simply a description of a relationship. When we examine these two components—the frontend and the server—we find they also form a client-server relationship. The UI sends requests to the server, and the server responds to the UI. Thus, the operator’s interface is indeed functioning as a client to the C2 server, earning it the name “C2 client.”
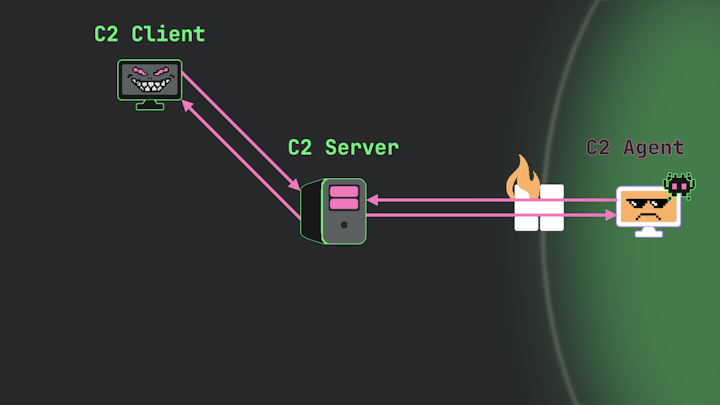
Image 9.
A Simple Example
To illustrate how these three core components work together, let’s use a simple example: the operator wants to run the “whoami” command on the target system.
The operator issues this command through the C2 client interface, which sends it to the server. When the C2 agent next checks in with the server asking “Do you have a job for me?”, the server responds, “Yes, I want you to run the command ‘whoami’.”
The agent receives these instructions, executes the command, and captures the result—in this case “mr.derp.” During its next check-in with the server, it serializes and encrypts this response before sending it back.
Since the C2 client and server typically maintain a persistent connection (WebSockets being a particularly popular choice), as soon as the server receives the result, it immediately forwards it back to the client interface where the operator can view it.
This represents one complete cycle in the basic setup of a C2 framework. The command flows from operator to target system, and the result flows back, all through the central coordinating server. Let’s also explore some common variations on this basic structure you’re likely to encounter.
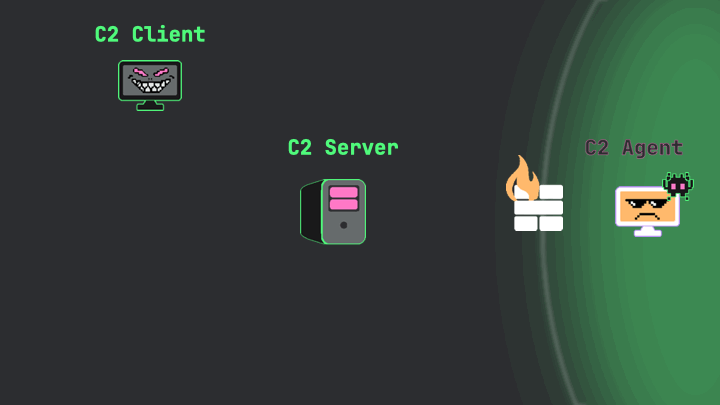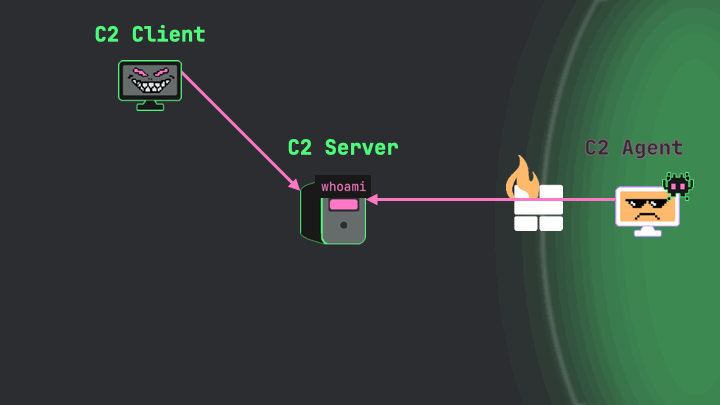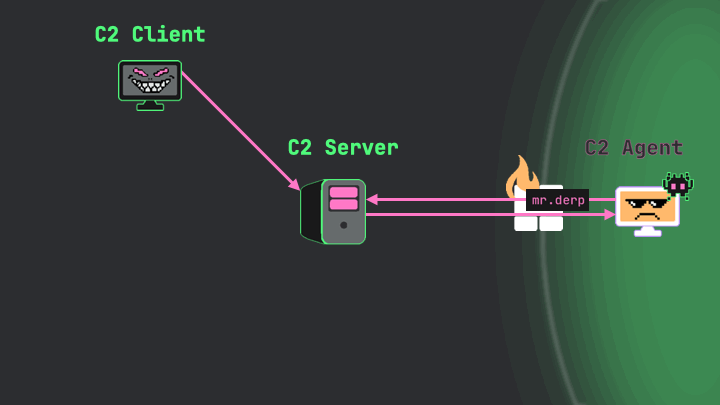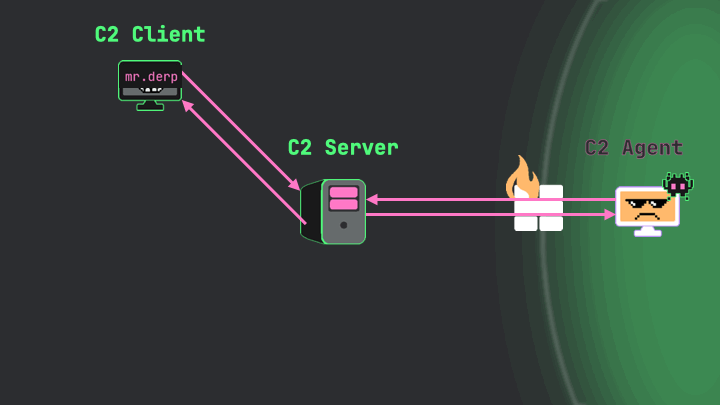
Image 10.
Multiple Agents
The first important variation to understand is that there can be multiple compromised systems on the target network. For example, after successful lateral movement, an attacker might have two or more systems within the corporate LAN running C2 agents.
Each of these additional agents could communicate outbound to the same C2 server as the initial compromise. However, they might also connect to entirely different servers. This is a common pattern where the operator establishes a “backup” (also known as a “zombie”) agent.
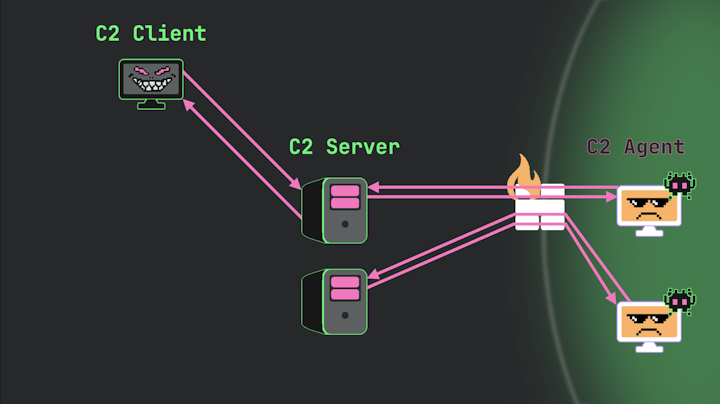
Image 11.
This zombie agent typically maintains a much lower profile—connecting back to its server less frequently and generating minimal network traffic. Should the primary agent and server be discovered and blocked by defenders, the operator can simply switch to using this backup pair as their new primary server and agent. This provides resilience against detection and remediation efforts.
Agent to Agent Communication
Consider another scenario: the operator has pivoted onto a restricted subnet that should not communicate outbound at all—perhaps it’s a data server isolated on its own network segment. In this case, the agent on this system won’t connect directly to a C2 server on the internet.
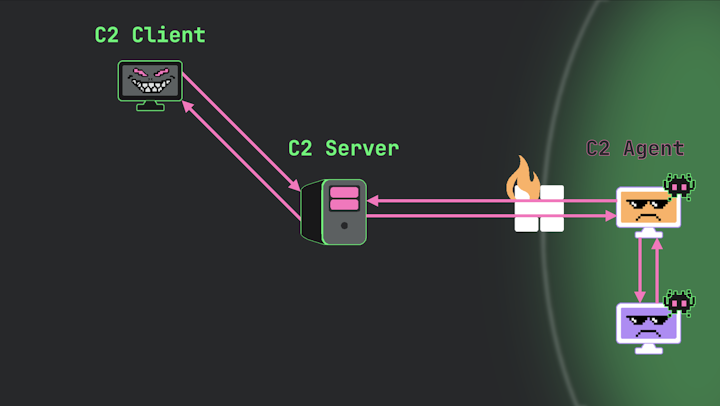
Image 12.
Instead, this agent communicates “agent-to-agent” with the first compromised agent using internal protocols like named pipes, SMB, or various other methods. While it still exchanges commands and results with the server, all this traffic proxies through the first C2 agent, which maintains the only connection to the outside.
Redirectors
Another common element you might encounter in C2 infrastructures are redirectors. A redirector functions as a proxy or forwarder positioned between the server and the agent, providing an effective way to hide the true identity of the C2 server by creating an additional layer of separation.
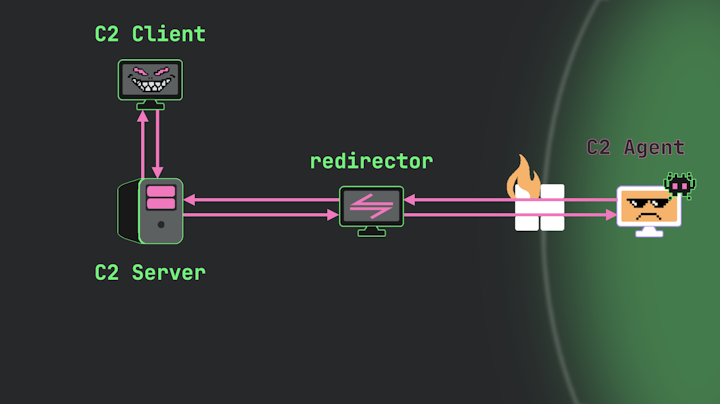
Image 13.
If security analysts were to capture network traffic on the victim LAN, the communication would appear to be flowing outbound to the redirector, not to the actual C2 server. This obscures the attacker’s core infrastructure.
Redirectors are typically deployed as simple, inexpensive cloud virtual machines that attackers can easily rent. This creates a significant advantage: if a redirector is discovered and blocked by defenders, it’s much easier and less disruptive to replace than having to rebuild the entire C2 server infrastructure. In this way, redirectors function as an insurance policy —they minimize the impact if part of the infrastructure is discovered, allowing operations to continue with minimal interruption.
Multiple Redirectors
Further, attackers can also of course employ multiple redirectors—two, three, or as many as needed. This approach provides resilience since operations can continue unimpeded if one redirector is discovered.
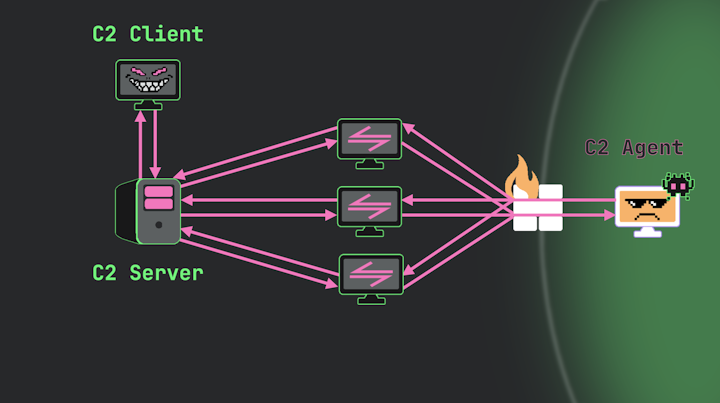
Image 14.
Another significant advantage of using multiple redirectors is the enhanced network evasion capabilities they provide. This works in two primary ways. First, it dilutes the amount of traffic going to any single system. The more traffic directed to a specific host—whether measured by duration or connection count—the more likely that connection will attract security scrutiny.
But it also provides a powerful network evasion technique due to what’s known as a host rotation strategy. How attackers choose to rotate communication between multiple redirectors can significantly disrupt predictable patterns, making detection more difficult. There are several approaches to this rotation.
The simplest—and arguably weakest—method is basic sequential rotation: A, B, C, A, B, C, with one connection per host. This provides the benefit of traffic dilution but little else.
Alternatively, attackers might randomize the choice, where each time a connection is needed, the agent randomly selects A, B, or C. This is effective at disrupting patterns in the short term, but over longer periods, predictable distributions emerge—just as flipping a coin enough times will eventually approach a predictable 50/50 distribution.
A more sophisticated approach combines random selection with variable timing: select A, B, or C randomly, then maintain that connection for a random duration between, say, 10 and 100 minutes before repeating the process. While many other strategies exist, the key insight is that this additional layer of infrastructure, with multiple possible communication endpoints, gives the C2 framework another technique for concealing its presence on the network.
Multiple Client UIs
It might also not be surprising that even in a simple setup most C2 frameworks will allow multiple client UIs. That’s because of course a campaign might involve multiple operators, and so for example if there are 3 operators part of a campaign, they’ll each have their own UI which they can use to interact with the server.
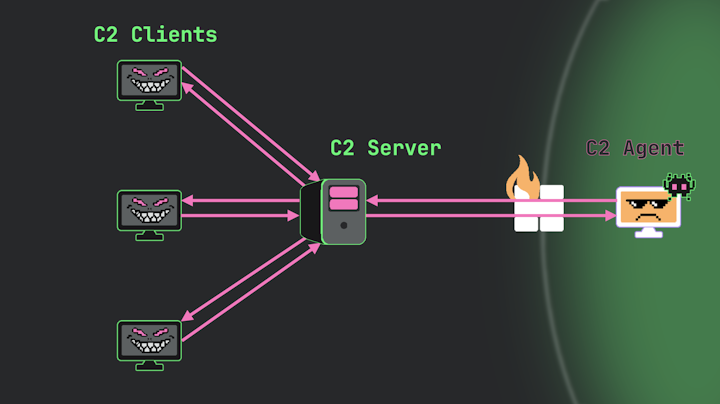
Image 15.
This collaborative capability is particularly valuable in larger operations where different team members might have different specialties or responsibilities. And some frameworks like Mythic take this a step further, allowing you to assign different levels of permissions to different operators. This means you could have junior operators with limited capabilities, while more experienced team members might have full access to all the framework’s functions.
Combinations
It’s important to understand that these patterns aren’t mutually exclusive – in fact, they’re designed to work together. In sophisticated attacks, you’ll typically see a complex ecosystem rather than just isolated components. Imagine a single operation utilizing multiple redirectors to distribute traffic, several compromised hosts communicating both outbound to different servers and laterally to each other, all while multiple operators collaborate through their individual UIs connected to a central command server.
The specific architecture an adversary deploys depends on three main factors: the campaign’s complexity (is this a quick smash-and-grab or a long-term intelligence operation?), the security controls they’re facing (how sophisticated is the target’s defensive posture?), and the skill level of the operator(s) conducting the attack. More sophisticated adversaries, particularly nation-state actors, might implement elaborate infrastructures with multiple layers of redundancy, while less sophisticated actors might use simpler setups that are easier to detect and disrupt.
Conclusion
We’ve covered significant ground in this first article on Command and Control frameworks. We began with the foundational concept that malware doesn’t break rules but bends them, and that at its core, a C2 framework is simply a specialized implementation of the client-server model.
We explored how the client-server relationship isn’t fixed to specific machines but rather describes a dynamic relationship between applications. Using our corporate network example, we followed the journey from initial phishing compromise to the establishment of a persistent C2 agent communicating outbound to a C2 server—and why this direction matters due to how firewalls typically allow outbound connections while blocking inbound ones.
We clarified terminology, noting that the implant on the victim machine goes by many names (Beacon, Demon, Grunt, Implant), but we’ll prefer “C2 Agent,” while the operator’s interface to the C2 server is typically called the “C2 Client.”
Through a simple example, we walked through a complete operational cycle—from command issuance to execution and result reporting. Then we explored variations: multiple agents communicating with one or more servers, agent-to-agent communication for pivoting into restricted networks, and redirectors that add resilience and stealth to operations.
Understanding these concepts is valuable for anyone defending against modern threats. By recognizing C2 architecture and communication patterns, we can better identify and disrupt malicious operations before attackers achieve their objectives.
In our next article, we’ll build on these foundations to explore how threat groups employ C2 frameworks in real-world campaigns. Until then, remember that understanding how attackers operate is often the first step in building effective defenses. The more we demystify these concepts, the better equipped we all are to protect our systems and data.
Live Long and Prosper,
Faan
The Beginner’s Guide to Command and Control – Part 2 >

Faan is a security researcher specializing in detecting post-exploitation malware, with a focus on network communication. He likes exploring threat hunting via a purple team approach by simulating adversarial activity to develop novel threat hunting detections. He also loves building covert channels and unusual malware communication methods, creating threat emulation tools that inform new detection vectors.