Extracting Lines of Interest From Zeek Logs

Overview
Imagine that you’re looking at a potential issue that shows up in a Zeek log file. Instead of attaching the entire log file to a response ticket it might make sense to extract just the lines relevant to this issue and attach just those lines to save space – and not share something else that might need to stay private!
In the following examples we’ll assume that the relevant DNS traffic is between local system 10.0.0.14 and remote system 8.8.8.8 (one of Google’s public DNS servers).
Steps
We need to 1) make a temporary directory to accept the new logs files, 2) for each log get all the raw lines from the existing logs, and 3) request the lines of interest and all the headers. We also need to save this output to a brand new file in the temporary directory.
Make a Temporary Directory for the Filtered Logs
Find a location with enough space to hold the output files. In this example I’ll assume you have enough space in your home directory. Feel free to name the output directory to something that indicates what you’re filtering.
mkdir -p "$HOME/filtered"
The logs we send to this directory will overwrite any similarly-named logs from previous runs, so it can’t be the same directory as the original logs.
Get the Raw Lines From the Existing Logs
Let’s say we’re only interested in extracting lines from the conn logs. Here’s the way to loop through each one. You’ll need to change the “cd” command to change to the directory containing the original logs:
cd /opt/zeek/logs/2025-06-18
for one_log in conn.*.log.gz ; do
: #Do something with "$one_log", sending the result to "$HOME/filtered"
done
The above loop will execute whatever command(s) you place between “for” and “done” one time for each file whose name starts with “conn.” and ends in “.log.gz” in the /opt/zeek/logs/2025-06-18 directory. On each pass through the loop the “one_log” variable holds the name of the log file (whose value can be accessed as $one_log .)
We’re going to use zcutter (see https://github.com/activecm/zcutter/ ) to read the log files because it understands multiple input log file formats and automatically handles decompressing files in the background. Here’s how we’d read those files and send them in their original format (no changes other than decompressing them) to the output directory:
cd /opt/zeek/logs/2025-06-18
for one_log in conn.*.log.gz ; do
#Read "$one_log", copying the original file to "$HOME/filtered/"
zcutter -C -t -r "$one_log" \
>"$HOME/filtered/${one_log%.gz}"
done
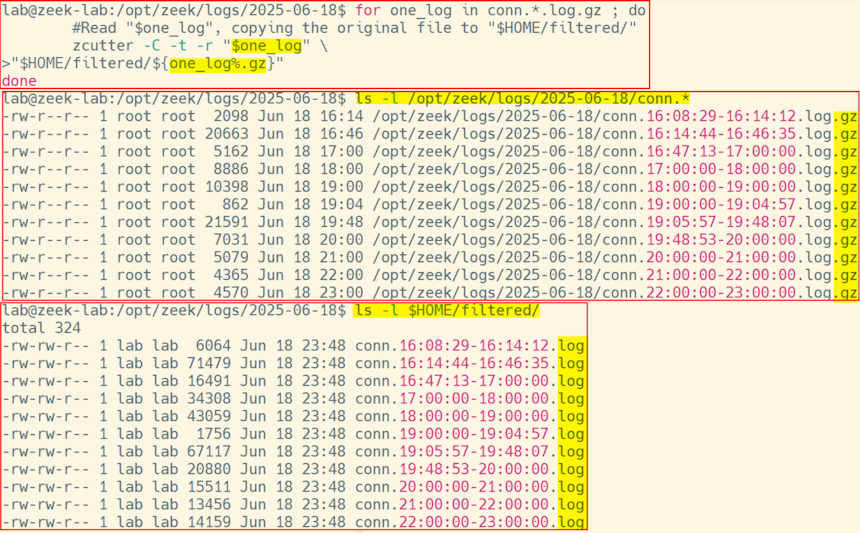
Image 1: Compressed Zeek logs extracted in a tabular format to a different location as log files.
The “-C” requests all header lines. The “-t” says we want to force the output to be in TSV (tab-separated) log file format since that’s easier to filter in the next step. The “-r” option (which must be the last one on the command line) precedes a list of all logs to read. You can see all the command line options by running zcutter -h .
Because the output file is uncompressed we’ll remove the “.gz” from it when we create it by using “${one_log%.gz}”. As an example, if “one_log” is set to ‘conn.07:00:00-08:00:00.log.gz’, the output file we create with this will be ‘conn.07:00:00-08:00:00.log’ .
The backslash at the end of the zcutter line (with nothing after it) tells bash that this command continues on the next line. This allows us to break up long commands and make them a little more readable.
Get Just the Lines of Interest and the Headers
Now we need to do some filtering. As we saw above the zcutter command just prints all the lines in the (uncompressed) log file. The “>” takes those lines and sends them verbatim to the (same-named) log file in the output directory. If we want to filter the output we need to put the filter between those two. Here’s an example of requesting both the Zeek header lines and all lines that contain the characters 8.8.8.8 :
cd /opt/zeek/logs/2025-06-18
for one_log in conn.*.log.gz ; do
#Read "$one_log", copying the original file to "$HOME/filtered/"
zcutter -C -t -r "$one_log" \
| egrep '(^#|[[:space:]]8\.8\.8\.8[[:space:]])' \
>"$HOME/filtered/${one_log%.gz}"
done
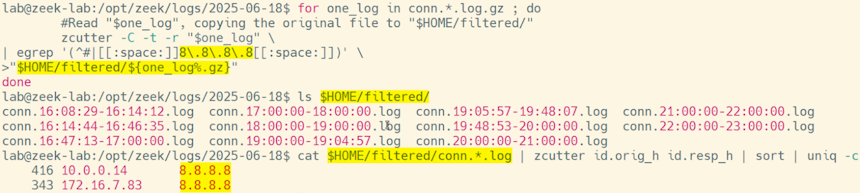
Image 2: Compressed Zeek logs filtered by a single IP address, and extracted to a different location as log files.
We’re using the “egrep” command that allows us to ask for lines that match something or something else (the vertical pipe “|” between “#” and “[” separates the something from the something else.) We want every line that starts with a “#” (the comment character that Zeek uses for its headers.) We also want every line that has the IP address 8.8.8.8. Because the periods used in IP addresses have a special meaning in grep and egrep we need to say we want to match an actual period by putting a backslash in front of each one, like: \. . Finally, we want to make sure there’s a tab character immediately in front of the address and immediately after so we don’t match other addresses like 238.8.8.8 or 8.8.8.85 . The “[[:space:]]” says to match any whitespace character like space, tab, or newline and will only match tab in this example.
The above loop will read each input log line and only send the ones that start with a # or have “8.8.8.8” somewhere in the line to the filtered output file.
You can do any processing you want in the above loop between the “|” and the “>” symbols. Just remember that when you select output lines to send along you also need to select the lines that start with a “#” or they won’t be correctly formatted as Zeek logs anymore.
Requesting Lines That Have Two Specific IP Addresses
This will be similar to the above, but in addition to having 8.8.8.8 I also want the line to have 10.0.0.14 . In this example I don’t care which address comes first as long as the line in question has both addresses:
cd /opt/zeek/logs/2025-06-18
for one_log in conn.*.log.gz ; do
#Read "$one_log", copying the original file to "$HOME/filtered/"
zcutter -C -t -r "$one_log" \
| egrep '(^#|[[:space:]]8\.8\.8\.8[[:space:]])' \
| egrep '(^#|[[:space:]]10\.0\.0\.14[[:space:]])' \
>"$HOME/filtered/${one_log%.gz}"
done
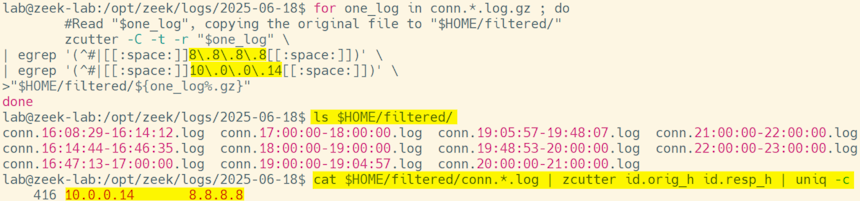
Image 3: Compressed Zeek logs filtered by multiple IP addresses, and extracted to a different location as log files.
We still have the original filter that requires 8.8.8.8 or # to be on the line, but we’ve added a second filter that requires 10.0.0.14 or # to be on the line as well. The practical way to read this is “send along all lines that start with a “#” or have both 8.8.8.8 and 10.0.0.14 somewhere on the line. Effectively this returns valid Zeek logs with all conversations between those two IP addresses, but not lines that have only one of those addresses.
Other Fields
We used IP addresses above because they’re commonly used for filtering and there are exactly two of them. However you’re welcome to filter on any field in the Zeek logs. Here’s an example of looking for multicast packets on udp port 5353 in dns format being sent to either 224.0.0.251 or ff02::fb :
cd /opt/zeek/logs/2025-06-18
for one_log in conn.*.log.gz ; do
#Read "$one_log", copying the original file to "$HOME/filtered/"
zcutter -C -t -r "$one_log" \
| egrep '(^#|[[:space:]]5353[[:space:]])' \
| egrep '(^#|[[:space:]]224\.0\.0\.51[[:space:]]|[[:space:]]ff02::fb[[:space:]])' \
| egrep '(^#|[[:space:]]udp[[:space:]])' \
| egrep '(^#|[[:space:]]dns[[:space:]])' \
>"$HOME/filtered/${one_log%.gz}"
done
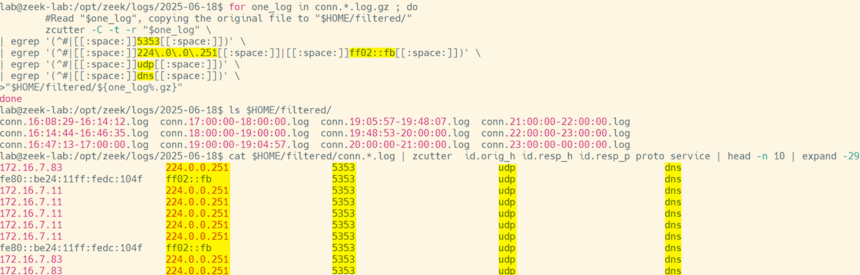
Image 4: Compressed Zeek logs filtered by IP addresses, port numbers & protocols, and extracted to a different location as log files.
The above pipeline doesn’t care in which order or in which columns these fields appear on the line – it just requires that all of them show up somewhere on the line. That makes filtering on a particular column whose value is, say, “F” tricky since that can show up in many columns. To do that you’ll probably want to use a tool like “awk” since it can return lines where a particular column contains a specific value.
Multicast DNS references:
https://www.activecountermeasures.com/finding-broadcast-and-multicast-traffic-on-your-network/
https://www.activecountermeasures.com/alternative-dns-techniques/
More Options
You can use any filter you’d like: grep, sed, awk, or a custom program of your choice. Just remember that every single tool in that pipeline has to 1) pass along the lines you care about, and 2) pass along all lines that start with a “#”.
While we filtered conn logs in the above examples this technique works for any standard Zeek log (anything whose first line is “#separator \x09”). Just remember to change the “for” line in the loop to your requested log type; here’s how you’d look for airplay devices in the dns logs:
cd /opt/zeek/logs/2025-06-18
for one_log in dns.*.log.gz ; do
#Read "$one_log", copying the original file to "$HOME/filtered/"
zcutter -C -t -r "$one_log" \
| egrep '(^#|[[:space:]]5353[[:space:]])' \
| egrep '(^#|[[:space:]]_airplay\._tcp\.local[[:space:]])' \
>"$HOME/filtered/${one_log%.gz}"
done
In the above examples we’ve asked zcutter to return all fields in the Zeek logs lines. zcutter will also happily return just some of the available fields by placing the field names on the zcutter command line in front of “-r”. Here’s our first example that requests just lines with 8.8.8.8, but we’ll pare down the output to just include the timestamp, source IP, source port, destination IP, destination port, and protocol:
cd /opt/zeek/logs/2025-06-18
for one_log in conn.*.log.gz ; do
#Read "$one_log", copying the original file to "$HOME/filtered/"
zcutter -C -t ts id.orig_h id.orig_p id.resp_h id.resp_p proto -r "$one_log" \
| egrep '(^#|[[:space:]]8\.8\.8\.8[[:space:]])' \
>"$HOME/filtered/${one_log%.gz}"
done
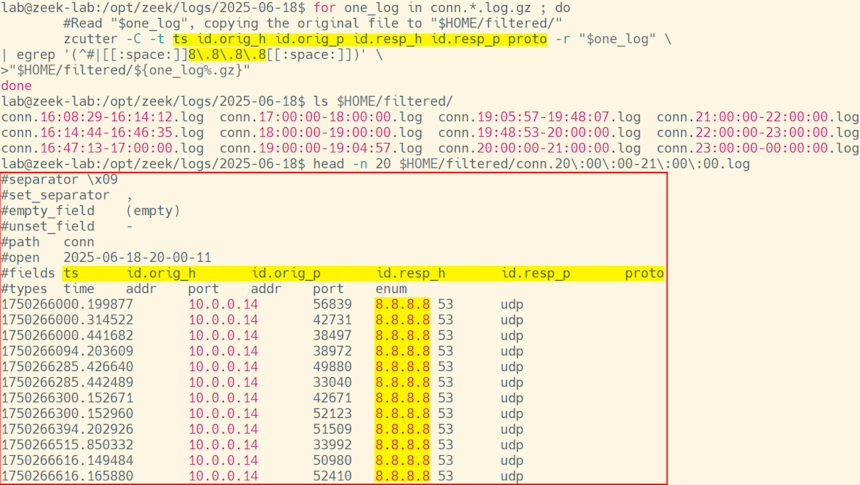
Image 5: Compressed Zeek conn logs filtered by IP addresses, conn.log headers to a different location as log files.
You’ll obviously need to include the columns on which you’re filtering. Since I want to filter on “8.8.8.8” above I need to make sure zcutter is showing both the source and destination IP addresses (id.orig_h and id.resp_h).
If you’d like to have the output files compressed to save space, run this command when you’re done creating them:
nice gzip -9 "$HOME/filtered/*.log"
Ready-To-Run Script
If you’d prefer to have a tool that’s prebuilt and does the above searching on up to 4 search terms, you can download extract-from-zeek.sh. Here are the steps:
mkdir -p ~/bin/ cd ~/bin/ wget https://raw.githubusercontent.com/activecm/zcutter/main/zcutter.py -O zcutter.py wget https://raw.githubusercontent.com/activecm/zeek-log-tools/main/extract-from-zeek.sh -O extract-from-zeek.sh chmod 755 zcutter.py extract-from-zeek.sh if ! type zeek-cut >/dev/null 2>&1 ; then ln -s zcutter.py zeek-cut ; fi
When you run it:
- Go to the directory that holds the original logs
- On the command line give the name of the directory where you’d like the output stored, then 1 to 4 search terms
Example:
cd /opt/zeek/logs/2025-06-18 extract-from-zeek.sh $HOME/filtered/ udp dns [[:space:]]53[[:space:]]
Log lines that have all three search terms will be written to the corresponding logs in $HOME/filtered/ .

Bill has authored numerous articles and tools for client use. He also serves as a content author and faculty member at the SANS Institute, teaching the Linux System Administration, Perimeter Protection, Securing Linux and Unix, and Intrusion Detection tracks. Bill’s background is in network and operating system security; he was the chief architect of one commercial and two open source firewalls and is an active contributor to multiple projects in the Linux development effort. Bill’s articles and tools can be found in online journals and at http://www.stearns.org.