Check the Stats, Your Threat Hunting is Probably Broken

I’m not trying to be adversarial, but I honestly think we need to have an open discussion about the definition of threat hunting and what the process should look like. As an industry, I think we are suffering from sunk cost fallacy by doubling down on trying to find the bad guys in our SIEM. Let’s talk about the statistics as to why threat hunting in a SIEM does not appear to be working, and why we need to try something new.
TL;DR Summary
When it comes to catching the bad guys, SIEM has many problems:
- Does not provide visibility of all systems that could be compromised.
- Data integrity is questionable.
- The platform is expensive in both time and cost to deploy.
- We spend more time running down false positives and tuning alerts than we do responding to true security events. This drives the cost even higher.
- SIEM adoption has exploded due to it being a requirement in nearly all security frameworks.
- Based on data from the major organizations that respond to incidents, SIEM has an absolutely horrible track record at detecting intrusions.
- Despite the increased adoption of SIEM, we’ve seen little to no improvement in outright detects, the amount of time adversaries spend on the network, or the cost outlay in recovering from an attack. If SIEM was effective, all of these attributes should show improvement.
- Network-based threat hunting can resolve many of these issues by relegating SIEM to more of a supportive role, rather than the primary tool for threat hunting.
- This combination can even solve some of our more advanced problems, like dramatically simplifying the steps to finding hidden processes.
A Bit About Me
I’m not big on talking about myself, but I feel the need to clarify my background before jumping into this topic. I’ve done central logging and alerting since the early ‘90s. It has a special place in my heart, as it’s one of the first security technologies I learned. I wrote my first book on security back in 1998, which included a section on centralized logging and alert management. I was a fellow instructor at SANS for many years, where I authored their first Security Information and Event Management (SIEM) course, as well as contributed similar content to multiple other courses. I’ve worked at, or consulted for, a range of organizations that span multiple sizes and verticals. So I’ve been around the block a few times when it comes to trying to centralize logging information with the intent of generating relevant and actionable alerts.
SIEM Visibility
One of the first challenges you run into with SIEM is that you never get a complete picture of all of the devices on the network. Not every device generates Syslog, JSON, or Windows event output that can easily be consumed. Even when they do, much of this data is focused on functionality, not security. So, the quality of the data collected can be suboptimal at best. It is also extremely challenging to implement any kind of validation check. It would be awesome if we could prevent all devices from talking on the network unless they are submitting logs to a central location, but this is frequently not possible. This means that the size of our blind spot is usually much bigger than we realize.
So, the first problem with SIEM is the lack of visibility. There is always some unknown portion of the network to which you are completely blind. If only desktops and servers could get compromised, this would be a manageable problem. However, we’ve seen a sharp increase in mobile devices, network hardware, IoT and IIoT compromises taking place. These are usually a significant portion of the blind spots in most environments.
Questionable Log Data Integrity
Our next challenge is that we are working with data that is being generated by a system that we suspect could be in a compromised state. Notice a logic issue with this situation? If we only convicted criminals that confessed to their crimes, there would be far fewer jails. I want to be clear; it’s not that attackers always taint the log entries. The challenge is that the logs could be modified, but we typically have no way of authenticating the integrity of the data being collected.
So, not only are we collecting log entries from only a portion of the network, but we also have a questionable level of confidence in the portion we do actually collect.
Deciding What to Log
Ask a vendor or a vested industry professional what you should be logging, and the typical answer is “everything.” As part of writing this blog, I asked ChatGPT what were the minimum Windows event IDs that should be centrally logged from every system, and it produced 25+ specific ID numbers and some additional vague descriptions that would probably add another 10-15 more. Multiply this by the number of systems on the network, and this can be a substantial amount of data. Keep in mind that data collection is not free. It results in a processor hit to the local system, as well as a bandwidth hit on the network. Further, all this data is going to slow down centralized processing on the SIEM. Queries and reports will run much slower.
I think the reason we get a vague/excessive answer to this question is that, historically, identifying compromises via SIEM data has not been very effective (more on this later). There is no short list of magic log entries we can identify which will tell us when the bad guys have breached our network. This results in both inconsistent and excessive advice on what data to collect. Do I really need to see file or registry key permission changes? These have an exceptionally high false positive rate and, if we do identify a system as compromised, we are either going to nuke it or perform a forensic analysis for these data points anyway. So, in many cases, the data we are collecting is killing performance and could be more efficiently addressed through other means.
Deployment Investment
For a small organization or test lab, SIEM deployment can be pretty straight forward. For medium to large environments, there are a lot of moving pieces. The SIEM needs a way to accept and verify the submitted log entries. We need a way to cache inbound data in case the quantity exceeds the system’s ability to consume these entries. Upon receipt, we then need a way to normalize the data into a consistent format that can be processed by the system (example: log data from Windows versus Linux versus network hardware is formatted very differently). We also need to work out data processing, indexing and searching, log retention, and a number of other parameters.
So, our next challenge with SIEM is that it requires a lot of resources, both financially and in work hours, just to get it into an initial state where we can start using it. This means that right out of the gate, it can be non-consequential to achieve a positive return on investment (ROI) from our SIEM.
Managing Alerts or Managing the SIEM?
Look at your typical SOC and you will find multiple analysts. I want to ask an uncomfortable question: Are these analysts managing security events or are they managing the SIEM? In other words, are our networks under constant bombardment by miscreants that are frequently breaching the perimeter and running wild on the network, thus requiring multiple analysts to respond? Or is the analyst’s job more about the care and maintenance of the SIEM in a Sisyphus-like attempt to investigate and silence all of the false positives? From my experience, it’s more of the latter.
So our next challenge with SIEM is that it needs constant attention, usually from a whole team of analysts. Unlike a firewall or authentication system that needs very little attention once it’s up and running, SIEM is a constant drain on resources. This makes achieving a positive ROI on SIEM even less likely.
Is SIEM Effective at Catching the Bad Guys?
To me, the title of this section is the most important question we need to be asking. If SIEM is effective at catching the bad guys, and it is capable of reducing the cost of recovery, then our chances of achieving a positive ROI will increase, and we can forgive many of the challenges identified above. There are some great annual reports that identify how well we are doing at catching the bad guys. I personally avoid MSSP or vendor reports that may present a limited or colored view. As an example, a company that gets paid to keep the bad guys out of their customer’s network has a financial motivation to downplay the number of times their product and/or service has failed. My favorite reports are from Verizon, Mandiant, and IBM. These companies get called in as part of the incident response process.
Validating the Results
I also like to ensure that Ransomware and Advanced Persistent Threat (APT) metrics are not lumped together, and that triggered ransomware does not get recorded as detecting the attack. Doing so incorrectly skews the data. Think of it this way — imagine your house gets broken into and all of your electronics get stolen. The perpetrator shows up at your door the next morning and admits to the crime. Would you go on social media and brag about the local cops solving the crime in less than 12 hours? Certainly not. Labeling ransomware that has announced itself as a “detection event” is much the same thing. If the report shows a sharp drop in detection time once ransomware was included in, that should be a red flag.
Show Me the Data
I highly recommend that you take the time to review the above mentioned reports. From my experience, when you aggregate these reports, you see some disturbing trends:
- A majority of attacks are detected by outside third parties, not the organization itself. This metric has been relatively steady for many years.
- Most studies show that “dwell time,” the time between initial compromise and detection, is over three months for APT and has been relatively unchanged for many years.
- For the studies that do show a reduction in dwell time, the cost of recovery has remained consistent. In other words, if we are actually detecting attacks more quickly, we would expect to see the cost of recovery go down as well. This has not been the case. It’s common to see a misalignment in these statistics when ransomware detection has been incorrectly added to the data pool. When in doubt, follow the money.
- In some business verticals, the percentage of attacks that have been detected by the organization’s SIEM is as low as 2%. In other words, for every 50 times the network actually gets breached, you can expect the SIEM to detect one of those events.
SIEM Adoption Is at an All-Time High
I think it’s important to note that SIEM has seen a steady increase in adoption. Today, it is a requirement of every major security framework. So, if you are PCI, HIPPA, SOC II, etc. compliant, you are expected to be using a SIEM. Again, if threat hunting within the SIEM ecosystem was actually effective at catching the bad guys, we would expect to see detection times go down, internal detection rates go up, and an overall improvement in the cost of recovery. According to the data, that has not been the trend.
Why Do We Keep Poking Our Eyes With Sharp Sticks?
So if SIEM has all of the problems mentioned above, and the data is showing it to be ineffective, why do we keep using it? Why is it being recommended by highly regarded professionals in the field? Why is it a requirement by so many security frameworks? Unfortunately, I feel we have a number of different factors coming into play.
It Seems Like a Smart Idea
Back in the 1800’s, Hawaiian sugarcane farmers were struggling with rats decimating their crops. The rats came in on ships, so they had no natural predators. The sugarcane fields provided an abundant source of food, so the population flourished. The farmers decided to import Indian mongooses to control the rat population. This seemed like a smart idea at the time. Mongooses are avid diggers so they would be able to excavate the rat boroughs. They were known to eat rodents, so the rats would be an obvious food source.
You can probably guess where this is going. Mongooses hunt during the day. Rats only come out at night. So the two species rarely crossed paths. Still needing a food source, the mongooses went after the local birds and their eggs. Many of these species were only found in Hawaii, and were hunted by the mongooses to extinction. With no natural predators, the mongooses flourished. Being avid swimmers, they found their way onto additional Hawaiian islands. To this day, Hawaii still has efforts to control the population.
So, what does SIEM have to do with mongooses? On initial scrutiny, both seem like really good ideas. It’s not until you get into the implementation phase that you notice things going sideways. If you have not done time doing security event management, it can be hard to understand just how much of a timesuck it can be. As mentioned above, SIEM can easily eat up more time and resources than any other security technology that we work with.
How Hard Can It Be?
To me, SIEM is a lot like a guitar. The concept is relatively straightforward. A guitar is just a hollow box with a couple of strings. How hard could it be to learn and master? With SIEM, we are just collecting log entries and checking them for suspect activity. How hard can it be to manage and master? As mentioned above, the reality is that you spend more time managing the SIEM directly than you do managing actionable alerts. Like a horse with a carrot dangled in front of its head, we keep prodding forward thinking the goal is just a little further ahead. This leads us into sunk cost fallacy.
Sunk Cost Fallacy
Sunk cost fallacy describes a human nature whereby it can be challenging to navigate off of a path that we have already invested effort into pursuing. As an example, imagine playing a slot machine. It costs 25 cents every time you pull the handle. You are down $10 and trying to decide if you should keep playing. Statistically, the answer is obvious. We’ve played 40 times and lost every round. From a purely mathematical perspective, it would be illogical to keep going. The reality is that we will probably convince ourselves that the machine is now “hot” or that it simply must pay off eventually, if we just stay the course. The result is that we defy logic and keep dropping coins.
I think this condition accurately describes what we experience with SIEM. A lot of time and effort goes into deploying the system. Even more time and effort goes into tuning it. This causes us to factor in influences other than the current alternatives. We have invested a lot of time and effort that we can never get back. So, that becomes a factor in rationalizing that we should stay on the current path in the hopes that all of that time and effort will eventually pay off. In fact, cognitive bias may drive us to ignore or cherry pick what we are seeing to legitimize staying on a path that is not producing the desired results.
While I’m not a neuroscientist, I personally think dopamine plays a role in driving this behavior as well. Dopamine drives our motivation, curiosity, and ambition. You would literally starve yourself without dopamine, as you would lack the motivation to find food. While dopamine is important, too much dopamine can lead to addictive behavior. If the dopamine-driven action provides insufficient rewards to trigger the serotonin or oxytocin necessary to neutralize the dopamine, the motivation cycle will continue, potentially leading to addictive behavior. Constantly administering our SIEM without the gratification of finding an attacker can easily trap us in a similar cycle.
Wanting Our Skill Sets to Still Be Relevant
One of the things I love about security is that it is a constantly changing field. The technology is always evolving, with folks coming up with new and innovative ways to solve problems. Further, “cyber security” is actually a collection of multiple technology verticals or domains. Feel a bit stale always doing pentesting? There are a plethora of other security disciplines you can jump into. There are always new things to learn. If you embrace all of this change, it literally becomes impossible to get bored in this field.
However, some folks take a far more conservative approach to change. It could be that they do not trust new ideas or procedures until they have had an extended period of time to vet them out. It could be that change brings with it the fear of our current skill sets being less relevant. A good analogy would be programming languages. Over the years we’ve moved from Fortran, to Pascal, to C, to Java, to Python, to who knows what will come next. Over the years there have been people that have embraced the new languages and others that have conservatively refused. I think it’s safe to say that we have similar demographics in our industry.
So, Is SIEM Dead?
With all of the above said, I think SIEM still has its place, just not as the primary method of identifying adversaries on the network. Threat hunting is better done on the network itself, with SIEM in a more supportive role. This setup eliminates many of the challenges noted above.
- Provided you monitor at the perimeter, you will see all devices, regardless of platform, that could potentially be compromised.
- Network hunting is consistent. You use the exact same process to hunt Windows, Linux, Mac, network gear, printers, IoT, IIoT, mobile devices, or anything else connected to the network.
- No agents or config changes needed on each endpoint. If someone plugs a new device into the network, you can see it and you can hunt it.
- Attackers can corrupt log entries, but they can’t corrupt their packets. This means that the integrity of the data is always maintained.
- Attackers can hide processes, but they can’t hide their packets. This means that full visibility is always maintained.
- Network data is consistent. Since all of the above mentioned platforms are speaking IP, there is no need to normalize the data between them.
- You still have the potential for having to process large amounts of data, but tools like Zeek go a long way towards reducing that load. There are both open source and commercial options to solve this problem.
- You need a way to parse this data to hunt for potential command and control activity. Again, there are both open source and commercial options.
Sample Mini Threat Hunts
Let’s perform two example threat hunts. In the first example, we will start our hunt on the SIEM. In the second example, we will start our hunt on the network and move to the SIEM if/when we need additional data.
Starting on the SIEM
Consider the data in Figure 1. We see that the user “James Kirk” has been running notepad.exe. This would not even blip our radar, as notepad.exe is considered a benign application. There are probably no signatures or searches that focus on this binary. In fact, in the course of a threat hunt, we probably would not even notice this activity. Our threat hunt would be complete and we would sleep well at night thinking we are safe.
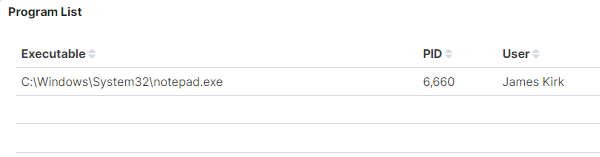
Figure 1: SIEM data on notepad.exe being executed
Starting on the Network
In this example, we will start our hunt on the network. Consider the data in Figure 2. We see that one of our internal systems is persistently connecting to a host on the internet. Given the frequency of the connections, there should be an identifiable business need behind this pattern. If our system is checking time, looking for patches, or similar, that would make sense. If these connections are to a random address we cannot identify, that would be a cause for concern. Let’s assume that we cannot immediately identify a legitimate business need for the connections.
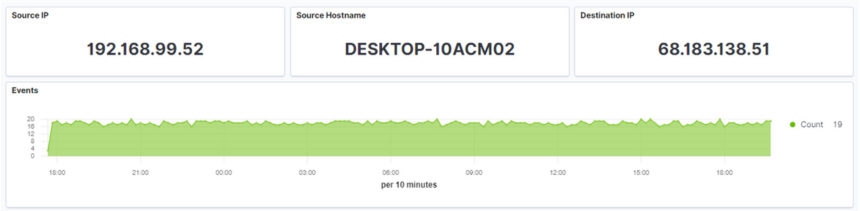
Figure 2: Network telemetry data
In this example, we’ve tuned our SIEM to only collect data on applications communicating on the network. In Windows speak, these would be ID 3 events. There are no fancy signatures or queries. Our SIEM never generates any alerts. All it does is collect this ID 3 data. With this in mind, let’s look at our SIEM to see which application was running on 192.168.99.52 when it was communicating with 68.183.138.51. The results are shown in Figure 3.
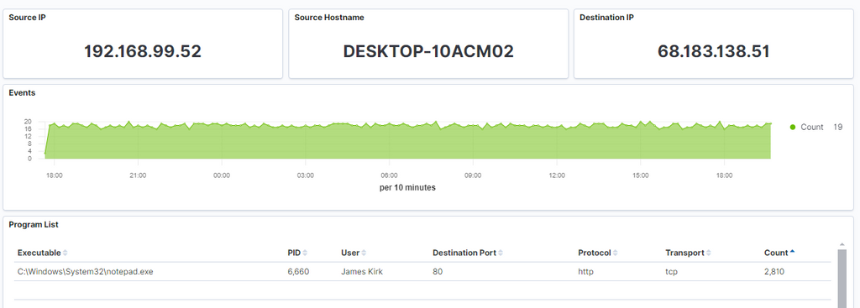
Figure 3: SIEM data and network telemetry combined
Note that this is the same SIEM data we looked at in the first example, but this time, we have context. Before, we simply saw a user running the application notepad.exe. However, in this context, we see that the application is responsible for outbound connections to an unknown address. This puts the execution of this application in a completely different light! Notepad should not be making connections to the internet, especially to a non-Microsoft IP address. So, while we thought we were safe when we did a SIEM-only hunt, by starting on the network, we can see that the system is most likely compromised and incident response is going to be required.
Finding Hidden Processes
Let’s upscale this example a bit and imagine we were dealing with an advanced adversary. We will assume the attacker is someone with the necessary skills to hide their running processes. How would we fare in each of the above examples with this new hurdle in place?
If we started our threat hunt on the SIEM, it’s over before it starts. Our adversary can hide their process execution, so there would be nothing in the logs for us to find. Game over; we’ve already lost.
In the second example, we would still see the suspect network behavior. However, this time, when we went to the SIEM, we would not see the application responsible for the connections. Without knowing ahead of time that we are dealing with an advanced adversary, the lack of application data could have two possible root causes:
- We are not collecting ID 3 data from this endpoint.
- It’s a savvy attacker who can hide their processes.
How can we tell which root cause is actually applicable in this situation? The steps are actually quite simplistic. To look for the application responsible for these connections, we used the following search query in our SIEM:
source.ip:192.168.99.52 and destination.ip:68.183.138.51
This query would identify the application running on 192.168.99.52 that is responsible for the connections going to 68.183.138.51. As we’ve stated, however, we are dealing with a hidden process, so no application data was returned.
So, here’s what we need to do. We simply change the above query to be:
source.ip:192.168.99.52
That’s all we need to do. We are now asking our SIEM to identify all applications on our system that made any network connections at all. One of two things is going to happen:
- We still see no data, which tells us that we are not collecting ID 3 info from this host.
- We see lots of other applications connecting across the network.
If the first situation is true, we need to start collecting those entries. If the second situation is true, it becomes a logic problem. Why is it that we can see all of these other applications connecting across the network, but we can’t see the one process responsible for this suspect traffic? The only logical answer is that the process responsible for these connections is hidden from view.
This, to me, really shows the strength of changing our way of thinking. In the first scenario, we were dead in the water. In the second, a junior analyst could document the activities of an extremely advanced attacker. The process change has dramatically improved our chances of success, while at the same time, lowered the required skill level for accomplishing the task. We’ve also reduced our overall cost of maintenance, as the SIEM no longer requires constant maintenance.
Summary
Cyber security can be intensive work, as we find ourselves constantly going down rabbit holes. However, on occasion, we need to pause and review the data to see if the processes we have in place are meeting expectations. The data shows that SIEM is clearly not as effective as we hoped it would be. It’s time to iterate and evolve so that we may find better options. Network-based threat hunting appears to show promise. Initial data shows it can be more effective than SIEM at identifying compromises. No technology is perfect, so I’m sure we will need to continue to iterate in the future. Only testing and time will tell for sure.

Chris has been a leader in the IT and security industry for over 20 years. He’s a published author of multiple security books and the primary author of the Cloud Security Alliance’s online training material. As a Fellow Instructor, Chris developed and delivered multiple courses for the SANS Institute. As an alumni of Y-Combinator, Chris has assisted multiple startups, helping them to improve their product security through continuous development and identifying their product market fit.